文章每周六持续更新,可以微信搜一搜「 荒古传说 」抢先阅读。
在上一篇文章 「《破壁MySQL》 - MySQL概述」 中我们简单介绍了MySQL 架构和 MySQL 存储引擎的相关知识,那么在这一篇文章中我们主要介绍的是 InnoDB存储引擎的索引实现原理,文章中在每介绍一部分知识点后都会给出知识点相对应的常见面试题以及答案,达到理论和实践相结合的效果。
面试题1:说说你对 MySQL 索引的理解?/InnoDB引擎中的索引策略,了解过吗?
索引是什么
索引(Index)是帮助MySQL高效获取数据的数据结构,所以说索引的本质是:数据结构。
索引的目的在于提高查询效率,可以类比字典、 火车站的车次表、图书的目录等
B+ Tree 原理
数据结构
B Tree 指的是 Balance Tree,也就是平衡树,平衡树是一颗查找树,并且所有叶子节点位于同一层。
B+ Tree 是 B 树的一种变形,它是基于 B Tree 和叶子节点顺序访问指针进行实现,通常用于数据库和操作系统的文件系统中。
B+ 树有两种类型的节点:内部节点(也称索引节点)和叶子节点。
内部节点就是非叶子节点,内部节点不存储数据,只存储索引,数据都存在叶子节点。
内部节点中的 key 都按照从小到大的顺序排列,对于内部节点中的一个 key,左子树中的所有 key 都小于它,右子树中的 key 都大于等于它,叶子节点的记录也是按照从小到大排列的。
每个叶子节点都存有相邻叶子节点的指针。
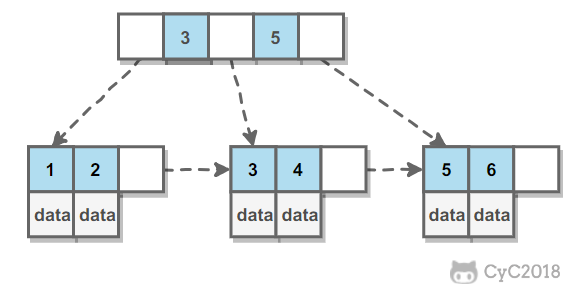
操作
查找
查找以典型的方式进行,类似于二叉查找树。起始于根节点,自顶向下遍历树,选择其分离值在要查找值的任意一边的子指针。在节点内部典型的使用是二分查找来确定这个位置。
插入
Perform a search to determine what bucket the new record should go into.
If the bucket is not full(a most b - 1 entries after the insertion,b 是节点中的元素个数,一般是页的整数倍),add tht record.
Otherwise,before inserting the new record
- split the bucket.
- original node has 「(L+1)/2」items
- new node has 「(L+1)/2」items
- Move 「(L+1)/2」-th key to the parent,and insert the new node to the parent.
- Repeat until a parent is found that need not split.
- split the bucket.
If the root splits,treat it as if it has an empty parent ans split as outline above.
B-trees grow as the root and not at the leaves.
删除
和插入类似,只不过是自下而上的合并操作。
常见树介绍
AVL 树
平衡二叉树,一般是用平衡因子差值决定并通过旋转来实现,左右子树树高差不超过1,那么和红黑树比较它是严格的平衡二叉树,平衡条件非常严格(树高差只有1),只要插入或删除不满足上面的条件就要通过旋转来保持平衡。由于旋转是非常耗费时间的。所以 AVL 树适用于插入/删除次数比较少,但查找多的场景。
红黑树
通过对从根节点到叶子节点路径上各个节点的颜色进行约束,确保没有一条路径会比其他路径长2倍,因而是近似平衡的。所以相对于严格要求平衡的AVL树来说,它的旋转保持平衡次数较少。适合,查找少,插入/删除次数多的场景。(现在部分场景使用跳表来替换红黑树,可搜索“为啥 redis 使用跳表(skiplist)而不是使用 red-black?”)
B/B+ 树
多路查找树,出度高,磁盘IO低,一般用于数据库系统中。
面试题2:B+ 树和 B 树的区别是什么?
B + 树与 B 树的比较
- B+ 树的内部节点并没有指向关键字具体信息的指针
- B+ 树的叶子节点具有指向左右叶子节点的指针
B+ 树的磁盘 IO 更低
B+ 树的内部节点并没有指向关键字具体信息的指针。因此其内部节点相对 B 树更小。
如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
B+ 树的范围查询、遍历效率高
B+ 树的叶子节点具有指向左右叶子节点的指针。因此其范围查询效率更高、遍历效率更高。
B+ 树的查询效率更加稳定
由于非叶子结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
B + 树与红黑树的比较
红黑树等平衡树也可以用来实现索引,但是文件系统及数据库系统普遍采用 B+ Tree 作为索引结构,主要有以下两个原因:
(一)磁盘 IO 次数
B+ 树一个节点可以存储多个元素,相对于红黑树的树高更低,磁盘 IO 次数更少。
(二)磁盘预读特性
为了减少磁盘 I/O 操作,磁盘往往不是严格按需读取,而是每次都会预读。预读过程中,磁盘进行顺序读取,顺序读取不需要进行磁盘寻道。每次会读取页的整数倍。
操作系统一般将内存和磁盘分割成固定大小的块,每一块称为一页,内存与磁盘以页为单位交换数据。数据库系统将索引的一个节点的大小设置为页的大小,使得一次 I/O 就能完全载入一个节点。
MySQL 索引
索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
B+ Tree 索引
是大多数 MySQL 存储引擎的默认索引类型。
因为不再需要进行全表扫描,只需要对树进行搜索即可,所以查找速度快很多。
因为 B+ Tree 的有序性,所以除了用于查找,还可以用于排序和分组。
可以指定多个列作为索引列,多个索引列共同组成键。
适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。如果不是按照索引列的顺序进行查找,则无法使用索引。
InnoDB 的 B+Tree 索引分为主索引和辅助索引。主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
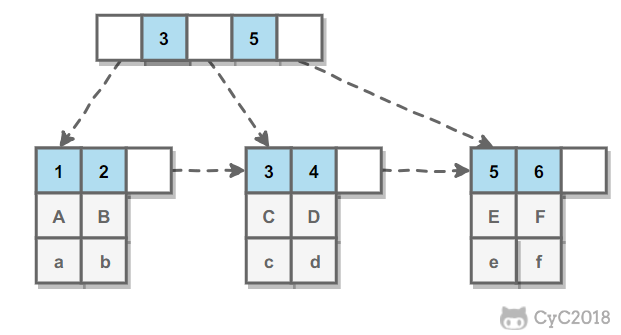
辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找,这个过程也被称作回表。
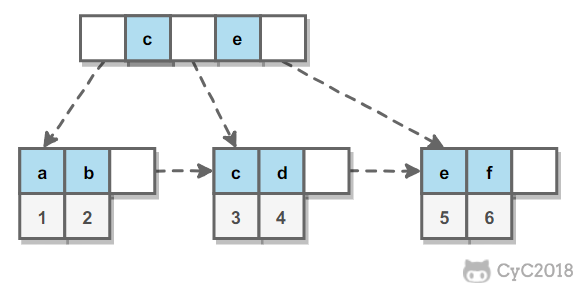
面试题3:分页SQL后期查询比较慢是什么原因?怎么处理?
比如:
1 | select * from table where type = 1 limit 0,10 |
这个没有问题,但是当进入分页后期就有问题了,比如下面这条sql:
1 | select * from table where type = 1 limit 100000,10 |
首先你需要了解B+树的实现原理,当做数据量比较大的分页的时候:
- (根据索引)找到起始位置(叶子结点)
- 沿着叶子结点向后遍历,过滤掉前面不在本次返回范围内的数据
- 找到目标数据后返回
从上述过程中可以看到,后期的主要耗时都在沿着叶子结点遍历上边,那么有没有什么方案可以省去这部分耗时呢?
有的,可以每次遍历结束后记录一下本页id最大值,然后在下一轮查询的时候,在where条件中加上这个id限制,这样可以保证每次查询速度都和第一页保持一致了。
1 | select * from table where type = 1 and id > max_id limit 100000,10 |
面试题4:什么是覆盖索引?
覆盖索引是要查询的数据列只从索引中就能够取得,不必回表查询主索引树。
要回答好这个问题,需要你了解上面介绍的B+树的实现原理,理解了原理回答起来就简单了。
哈希索引
哈希索引能以 O(1) 时间进行查找,但是失去了有序性:
- 无法用于排序与分组;
- 只支持精确查找,无法用于部分查找和范围查找。
InnoDB 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
全文索引
MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。
查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
全文索引使用倒排索引实现,它记录着关键词到其所在文档的映射。
InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
空间数据索引
MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询。
必须使用 GIS 相关的函数来维护数据。
索引的优点
大大减少了服务器需要扫描的数据行数。
帮助服务器避免进行排序和分组,以及避免创建临时表(B+Tree 索引是有序的,可以用于 ORDER BY 和 GROUP BY 操作。临时表主要是在排序和分组过程中创建,不需要排序和分组,也就不需要创建临时表)。
将随机 I/O 变为顺序 I/O(B+Tree 索引是有序的,会将相邻的数据都存储在一起)。
索引的使用条件
对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
对于中到大型的表,索引就非常有效;
但是对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
为什么对于非常小的表,大部分情况下简单的全表扫描比建立索引更高效?
如果一个表比较小,那么显然直接遍历表比走索引要快(因为需要回表)。
注:首先,要注意这个答案隐含的条件是查询的数据不是索引的构成部分,否也不需要回表操作。其次,查询条件也不是主键,否则可以直接从聚簇索引中拿到数据。
小结
这篇文章是《破壁》系列的第二篇文章,主要介绍了一下索引相关内容。
文中首先从数据结构、操作、常见树的比较等角度介绍了 B+ 树相关的原理知识。
其次着重介绍了一下 *InnoDB 的 B+ 索引的实现原理***。
老规矩,文中出现的面试题如下:
- 面试题1:说说你对 MySQL 索引的理解?/InnoDB引擎中的索引策略,了解过吗?
- 面试题2:B+ 树和 B 树的区别是什么?
- 面试题3:分页SQL后期查询比较慢是什么原因?怎么处理?
- 面试题4:什么是覆盖索引?
上面所有面试题都是在文中出现过的,如果如果答不上来可以回到文中再看一下答案以及相应的知识点。
参考资料
文章每周六持续更新,可以微信搜一搜「 荒古传说 」抢先阅读。
