最近刚刚和泽康和素鑫聊过这个问题,这里简单整理一下。
标题中的 ‘对于非常小的表,大部分情况下简单的全表扫描比建立索引更高效’ ,其实是问题 ‘索引的使用条件’ 的答案的一部分。完整答案是:
- 对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效
- 对于中到大型的表,索引就非常有效;
那么为什么对于非常小的表,大部分情况下简单的全表扫描比建立索引更高效呢?理由如下:
MySQL的默认存储引擎是InnoDB,在InnoDB中索引是通过 B+ 树实现的,MySQL的数据是存储在聚簇索引(聚簇索引也叫主键索引、一级索引)的叶子节点上。
在辅助索引(包括唯一索引和非唯一索引)的的叶子节点上存储着构成索引的字段和主键。
如果查询的字段不是索引的组成部分,就需要拿着从辅助索引中查到的主键值去聚簇索引中查询数据,这个过程也叫做回表。
所以,如果一个表比较小,那么显然直接遍历表比走索引要快(因为需要回表)。
注:首先,要注意这个答案隐含的条件是查询的数据不是索引的构成部分,否也不需要回表操作。其次,查询条件也不是主键,否则可以直接从聚簇索引中拿到数据。
这里有一个概念这里简单总结一下:
B+Tree 索引
是大多数 MySQL 存储引擎的默认索引类型。
因为不再需要进行全表扫描,只需要对树进行搜索即可,所以查找速度快很多。
因为 B+ Tree 的有序性,所以除了用于查找,还可以用于排序和分组。
可以指定多个列作为索引列,多个索引列共同组成键。
适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。如果不是按照索引列的顺序进行查找,则无法使用索引。
InnoDB 的 B+Tree 索引分为主索引和辅助索引。主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
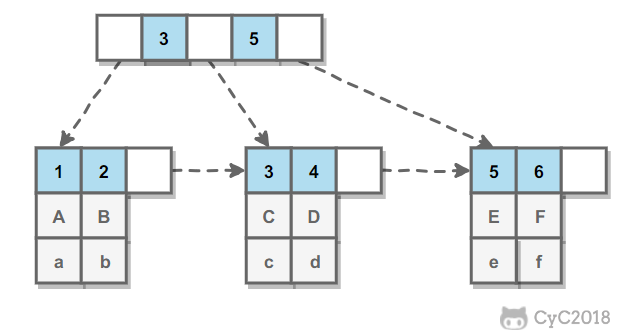
辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找。
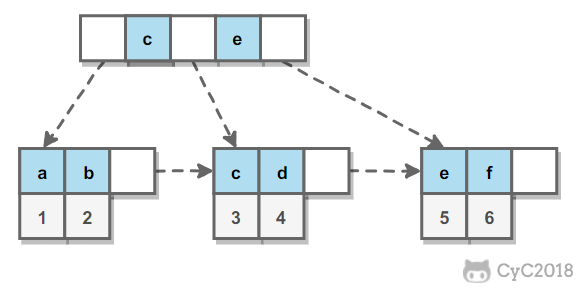
覆盖索引
索引包含所有需要查询的字段的值。
具有以下优点:
- 索引通常远小于数据行的大小,只读取索引能大大减少数据访问量。
- 一些存储引擎(例如 MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
- 对于 InnoDB 引擎,若辅助索引能够覆盖查询,则无需访问主索引(无需回表)。
索引的使用条件
对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
对于中到大型的表,索引就非常有效;
但是对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
