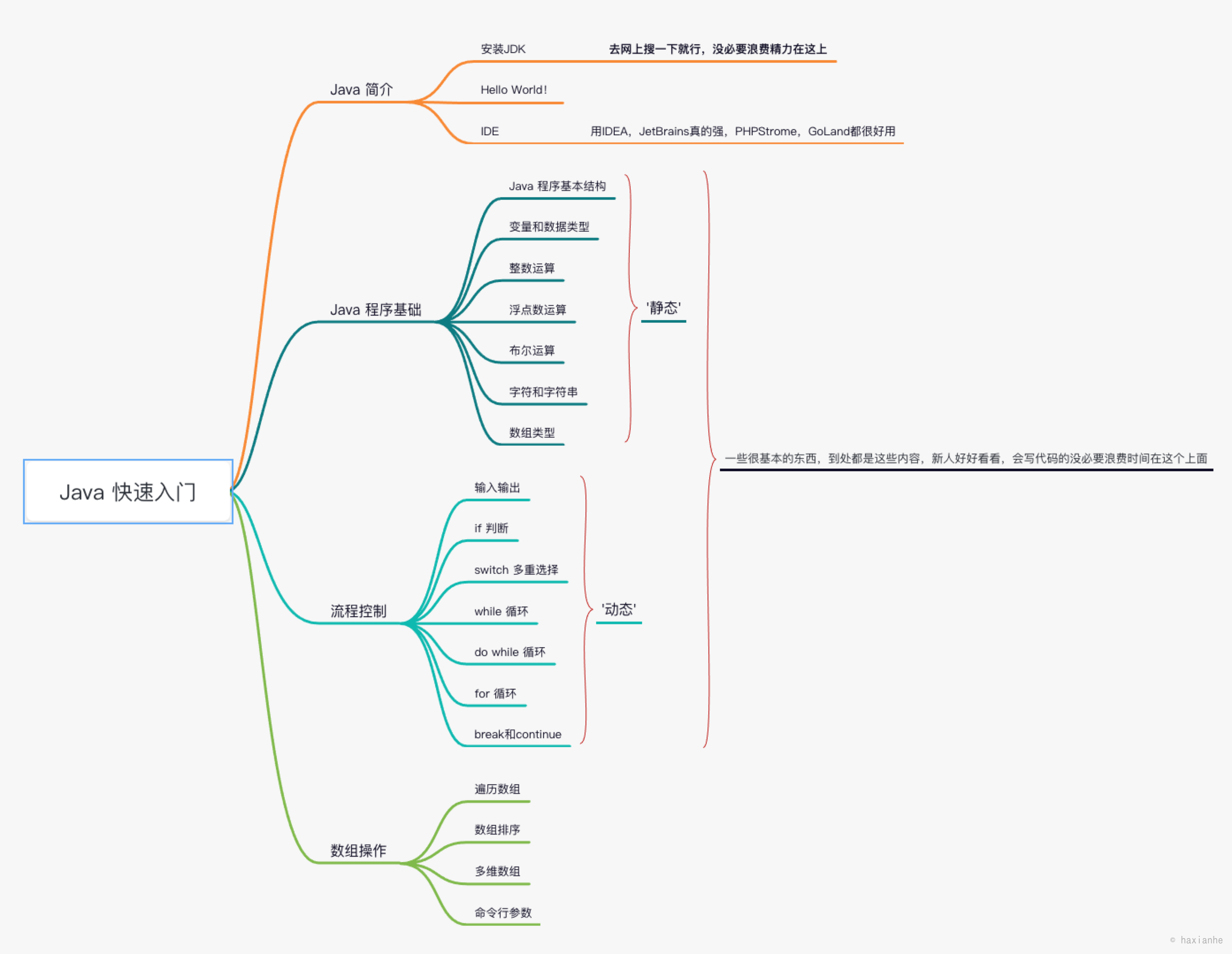
概述
Java最早是由SUN公司(已被Oracle收购)的詹姆斯·高斯林(高司令,人称Java之父)在上个世纪90年代初开发的一种编程语言,最初被命名为Oak,目标是针对小型家电设备的嵌入式应用,结果市场没啥反响。谁料到互联网的崛起,让Oak重新焕发了生机,于是SUN公司改造了Oak,在1995年以Java的名称正式发布,原因是Oak已经被人注册了,因此SUN注册了Java这个商标。随着互联网的高速发展,Java逐渐成为最重要的网络编程语言。
Java介于编译型语言和解释型语言之间。编译型语言如C、C++,代码是直接编译成机器码执行,但是不同的平台(x86、ARM等)CPU的指令集不同,因此,需要编译出每一种平台的对应机器码。解释型语言如Python、Ruby没有这个问题,可以由解释器直接加载源码然后运行,代价是运行效率太低。而Java是将代码编译成一种“字节码”,它类似于抽象的CPU指令,然后,针对不同平台编写虚拟机,不同平台的虚拟机负责加载字节码并执行,这样就实现了“一次编写,到处运行”的效果。当然,这是针对Java开发者而言。对于虚拟机,需要为每个平台分别开发。为了保证不同平台、不同公司开发的虚拟机都能正确执行Java字节码,SUN公司制定了一系列的Java虚拟机规范。从实践的角度看,JVM的兼容性做得非常好,低版本的Java字节码完全可以正常运行在高版本的JVM上。
随着Java的发展,SUN给Java又分出了三个不同版本:
- Java SE:Standard Edition
- Java EE:Enterprise Edition
- Java ME:Micro Edition
这三者之间有啥关系呢?
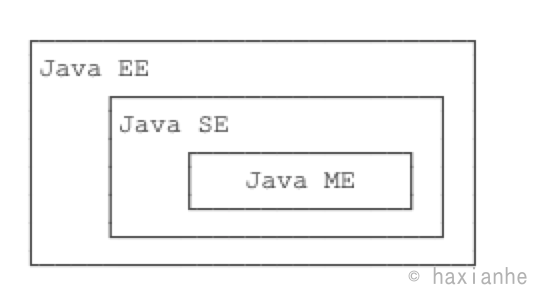
简单来说,Java SE就是标准版,包含标准的JVM和标准库,而Java EE是企业版,它只是在Java SE的基础上加上了大量的API和库,以便方便开发Web应用、数据库、消息服务等,Java EE的应用使用的虚拟机和Java SE完全相同。
Java ME就和Java SE不同,它是一个针对嵌入式设备的“瘦身版”,Java SE的标准库无法在Java ME上使用,Java ME的虚拟机也是“瘦身版”。
毫无疑问,Java SE是整个Java平台的核心,而Java EE是进一步学习Web应用所必须的。我们熟悉的Spring等框架都是Java EE开源生态系统的一部分。不幸的是,Java ME从来没有真正流行起来,反而是Android开发成为了移动平台的标准之一,因此,没有特殊需求,不建议学习Java ME。
因此我们推荐的Java学习路线图如下:
首先要学习Java SE,掌握Java语言本身、Java核心开发技术以及Java标准库的使用;
如果继续学习Java EE,那么Spring框架、数据库开发、分布式架构就是需要学习的;
如果要学习大数据开发,那么Hadoop、Spark、Flink这些大数据平台就是需要学习的,他们都基于Java或Scala开发;
如果想要学习移动开发,那么就深入Android平台,掌握Android App开发。
无论怎么选择,Java SE的核心技术是基础,这个教程的目的就是让你完全精通Java SE!
Java版本
从1995年发布1.0版本开始,到目前为止,最新的Java版本是Java 15:
- 时间 版本
- 1995 1.0
- 1998 1.2
- 2000 1.3
- 2002 1.4
- 2004 1.5 / 5.0
- 2005 1.6 / 6.0
- 2011 1.7 / 7.0
- 2014 1.8 / 8.0
- 2017/9 1.9 / 9.0
- 2018/3 10
- 2018/9 11
- 2019/3 12
- 2019/9 13
- 2020/3 14
- 2020/9 15
- 2021/3 16
Java 8 和 Java 11 现在业界用的比较多。
名词解释
初学者学Java,经常听到JDK、JRE这些名词,它们到底是啥?
- JDK:Java Development Kit
- JRE:Java Runtime Environment
简单地说,JRE就是运行Java字节码的虚拟机。但是,如果只有Java源码,要编译成Java字节码,就需要JDK,因为JDK除了包含JRE,还提供了编译器、调试器等开发工具。
二者关系如下:
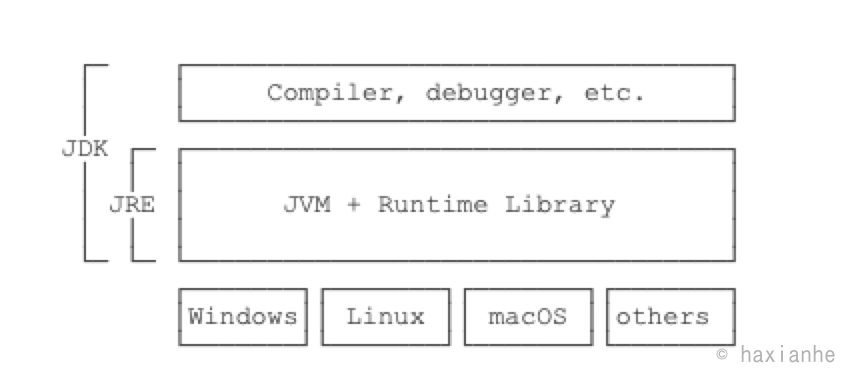
要学习Java开发,当然需要安装JDK了。
那JSR、JCP……又是啥?
- JSR规范:Java Specification Request
- JCP组织:Java Community Process
为了保证Java语言的规范性,SUN公司搞了一个JSR规范,凡是想给Java平台加一个功能,比如说访问数据库的功能,大家要先创建一个JSR规范,定义好接口,这样,各个数据库厂商都按照规范写出Java驱动程序,开发者就不用担心自己写的数据库代码在MySQL上能跑,却不能跑在PostgreSQL上。
所以JSR是一系列的规范,从JVM的内存模型到Web程序接口,全部都标准化了。而负责审核JSR的组织就是JCP。
一个JSR规范发布时,为了让大家有个参考,还要同时发布一个“参考实现”,以及一个“兼容性测试套件”:
- RI:Reference Implementation
- TCK:Technology Compatibility Kit
比如有人提议要搞一个基于Java开发的消息服务器,这个提议很好啊,但是光有提议还不行,得贴出真正能跑的代码,这就是RI。如果有其他人也想开发这样一个消息服务器,如何保证这些消息服务器对开发者来说接口、功能都是相同的?所以还得提供TCK。
通常来说,RI只是一个“能跑”的正确的代码,它不追求速度,所以,如果真正要选择一个Java的消息服务器,一般是没人用RI的,大家都会选择一个有竞争力的商用或开源产品。
参考:Java消息服务JMS的JSR:https://jcp.org/en/jsr/detail?id=914
Java 入门的内容都烂大街了,随便一本书里都有,这里就不浪费时间了。
这里我想说一下关于软件安装、环境配置、资料搜索的问题。我大学的时候就沉迷于这三件事情,浪费了许多珍贵的时间,我只想说你要时刻牢记你的目标是什么,不要在那里感动自己。这句话也送给我自己。
面向对象
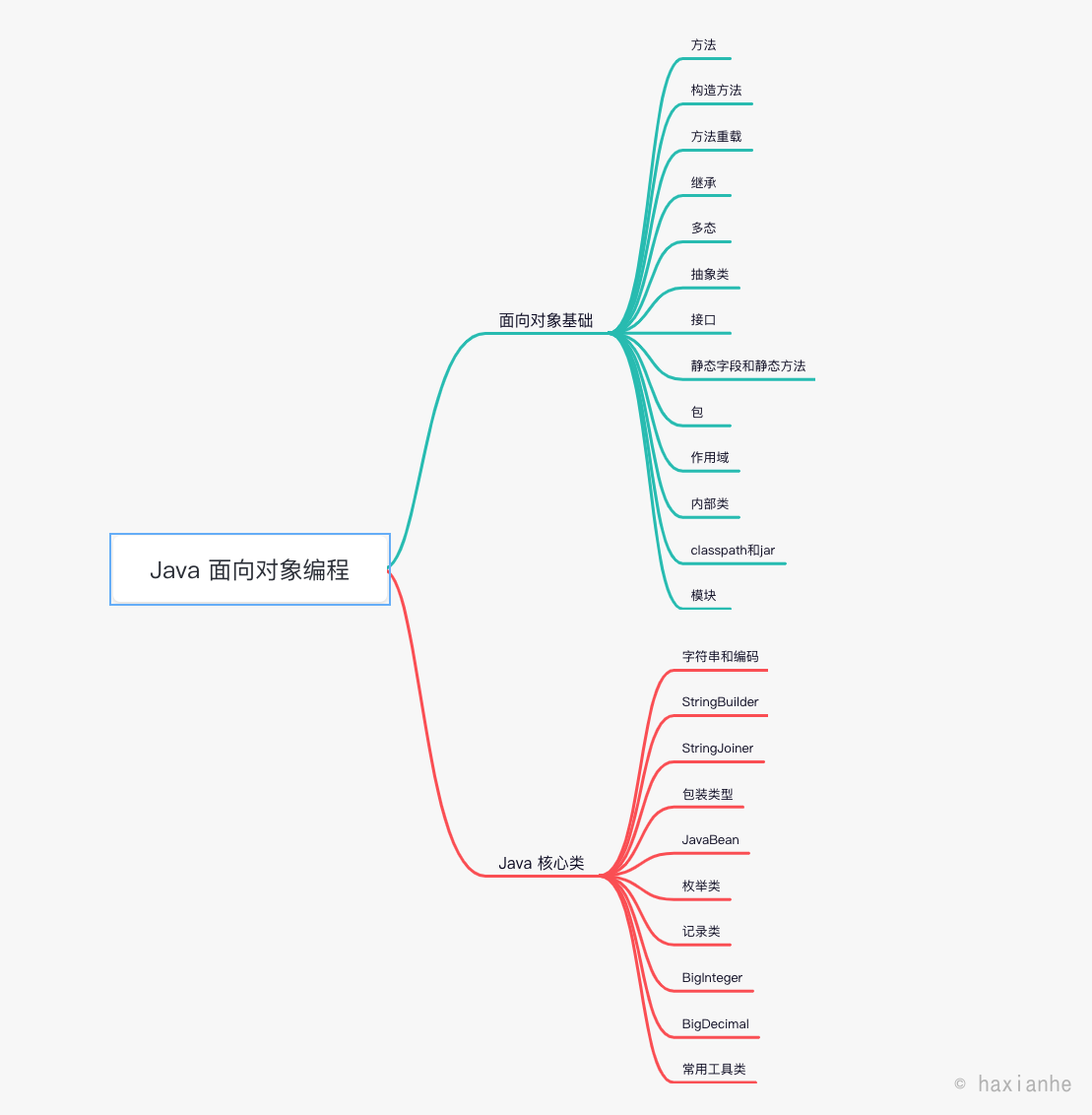
Java是一种面向对象的编程语言。面向对象编程,英文是Object-Oriented Programming,简称OOP。
那什么是面向对象编程?
和面向对象编程不同的,是面向过程编程。面向过程编程,是把模型分解成一步一步的过程。比如,老板告诉你,要编写一个TODO任务,必须按照以下步骤一步一步来:
- 读取文件;
- 编写TODO;
- 保存文件。
而面向对象编程,顾名思义,你得首先有个对象:
有了对象后,就可以和对象进行互动:
1 | GirlFriend gf = new GirlFriend(); |
因此,面向对象编程,是一种通过对象的方式,把现实世界映射到计算机模型的一种编程方法。
在本章中,我们将讨论:
面向对象的基本概念,包括:
- 类
- 实例
- 方法
面向对象的实现方式,包括:
- 继承
- 多态
Java语言本身提供的机制,包括:
- package
- classpath
- jar
以及Java标准库提供的核心类,包括:
- 字符串
- 包装类型
- JavaBean
- 枚举
- 常用工具类
异常处理
在计算机程序运行的过程中,总是会出现各种各样的错误。
有一些错误是用户造成的,比如,希望用户输入一个int类型的年龄,但是用户的输入是abc:
1 | // 假设用户输入了abc: |
程序想要读写某个文件的内容,但是用户已经把它删除了:
1 | // 用户删除了该文件: |
还有一些错误是随机出现,并且永远不可能避免的。比如:
- 网络突然断了,连接不到远程服务器;
- 内存耗尽,程序崩溃了;
- 用户点“打印”,但根本没有打印机;
- ……
所以,一个健壮的程序必须处理各种各样的错误。
所谓错误,就是程序调用某个函数的时候,如果失败了,就表示出错。
调用方如何获知调用失败的信息?有两种方法:
方法一:约定返回错误码。
例如,处理一个文件,如果返回0,表示成功,返回其他整数,表示约定的错误码:
1 | int code = processFile("C:\\test.txt"); |
因为使用int类型的错误码,想要处理就非常麻烦。这种方式常见于底层C函数。
方法二:在语言层面上提供一个异常处理机制。
Java内置了一套异常处理机制,总是使用异常来表示错误。
异常是一种class,因此它本身带有类型信息。异常可以在任何地方抛出,但只需要在上层捕获,这样就和方法调用分离了:
1 | try { |
因为Java的异常是class,它的继承关系如下:
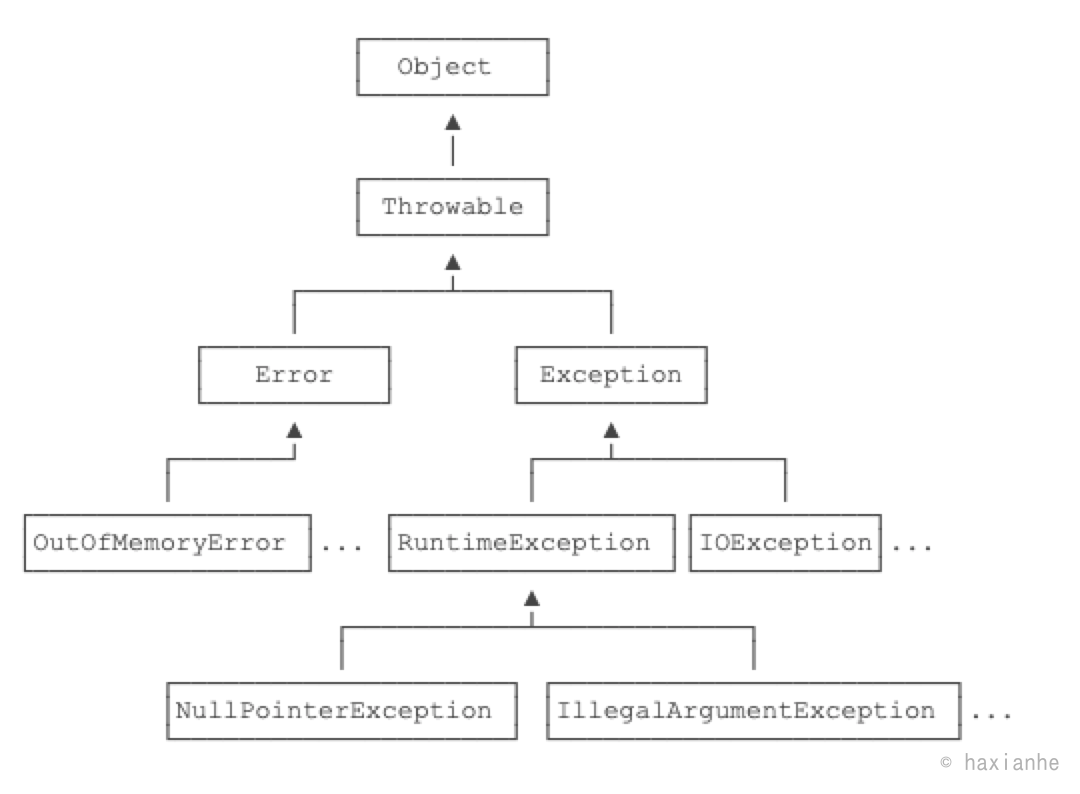
从继承关系可知:Throwable是异常体系的根,它继承自Object。Throwable有两个体系:Error和Exception,Error表示严重的错误,程序对此一般无能为力,例如:
- OutOfMemoryError:内存耗尽
- NoClassDefFoundError:无法加载某个Class
- StackOverflowError:栈溢出
而Exception则是运行时的错误,它可以被捕获并处理。
某些异常是应用程序逻辑处理的一部分,应该捕获并处理。例如:
- NumberFormatException:数值类型的格式错误
- FileNotFoundException:未找到文件
- SocketException:读取网络失败
还有一些异常是程序逻辑编写不对造成的,应该修复程序本身。例如:
- NullPointerException:对某个null的对象调用方法或字段
- IndexOutOfBoundsException:数组索引越界
Exception又分为两大类:
- RuntimeException以及它的子类;
- 非RuntimeException(包括IOException、ReflectiveOperationException等等)
Java规定:
必须捕获的异常,包括Exception及其子类,但不包括RuntimeException及其子类,这种类型的异常称为Checked Exception。
不需要捕获的异常,包括Error及其子类,RuntimeException及其子类。
注意:编译器对RuntimeException及其子类不做强制捕获要求,不是指应用程序本身不应该捕获并处理RuntimeException。是否需要捕获,具体问题具体分析。
捕获异常
捕获异常使用try…catch语句,把可能发生异常的代码放到try {…}中,然后使用catch捕获对应的Exception及其子类:
1 | // try...catch |
如果我们不捕获UnsupportedEncodingException,会出现编译失败的问题:
1 | // try...catch |
编译器会报错,错误信息类似:unreported exception UnsupportedEncodingException; must be caught or declared to be thrown,并且准确地指出需要捕获的语句是return s.getBytes(“GBK”);。意思是说,像UnsupportedEncodingException这样的Checked Exception,必须被捕获。
这是因为String.getBytes(String)方法定义是:
1 | public byte[] getBytes(String charsetName) throws UnsupportedEncodingException { |
在方法定义的时候,使用throws Xxx表示该方法可能抛出的异常类型。调用方在调用的时候,必须强制捕获这些异常,否则编译器会报错。
在toGBK()方法中,因为调用了String.getBytes(String)方法,就必须捕获UnsupportedEncodingException。我们也可以不捕获它,而是在方法定义处用throws表示toGBK()方法可能会抛出UnsupportedEncodingException,就可以让toGBK()方法通过编译器检查:
1 | // try...catch |
上述代码仍然会得到编译错误,但这一次,编译器提示的不是调用return s.getBytes(“GBK”);的问题,而是byte[] bs = toGBK(“中文”);。因为在main()方法中,调用toGBK(),没有捕获它声明的可能抛出的UnsupportedEncodingException。
修复方法是在main()方法中捕获异常并处理:
1 | // try...catch |
可见,只要是方法声明的Checked Exception,不在调用层捕获,也必须在更高的调用层捕获。所有未捕获的异常,最终也必须在main()方法中捕获,不会出现漏写try的情况。这是由编译器保证的。main()方法也是最后捕获Exception的机会。
如果是测试代码,上面的写法就略显麻烦。如果不想写任何try代码,可以直接把main()方法定义为throws Exception:
1 | // try...catch |
因为main()方法声明了可能抛出Exception,也就声明了可能抛出所有的Exception,因此在内部就无需捕获了。代价就是一旦发生异常,程序会立刻退出。
还有一些童鞋喜欢在toGBK()内部“消化”异常:
1 | static byte[] toGBK(String s) { |
所有异常都可以调用printStackTrace()方法打印异常栈,这是一个简单有用的快速打印异常的方法。
抛出异常
当某个方法抛出了异常时,如果当前方法没有捕获异常,异常就会被抛到上层调用方法,直到遇到某个try … catch被捕获为止:
1 | public class Main { |
NullPointerException
在所有的RuntimeException异常中,Java程序员最熟悉的恐怕就是NullPointerException了。
NullPointerException即空指针异常,俗称NPE。如果一个对象为null,调用其方法或访问其字段就会产生NullPointerException,这个异常通常是由JVM抛出的,例如:
1 | public class Main { |
如果遇到NullPointerException,我们应该如何处理?首先,必须明确,NullPointerException是一种代码逻辑错误,遇到NullPointerException,遵循原则是早暴露,早修复,严禁使用catch来隐藏这种编码错误。
Java使用异常来表示错误,并通过try … catch捕获异常;
Java的异常是class,并且从Throwable继承;
Error是无需捕获的严重错误,Exception是应该捕获的可处理的错误;
RuntimeException无需强制捕获,非RuntimeException(Checked Exception)需强制捕获,或者用throws声明;
不推荐捕获了异常但不进行任何处理。
反射
什么是反射?
反射就是Reflection,Java的反射是指程序在运行期可以拿到一个对象的所有信息。
正常情况下,如果我们要调用一个对象的方法,或者访问一个对象的字段,通常会传入对象实例:
1 | // Main.java |
但是,如果不能获得Person类,只有一个Object实例,比如这样:
1 | String getFullName(Object obj) { |
怎么办?有童鞋会说:强制转型啊!
1 | String getFullName(Object obj) { |
强制转型的时候,你会发现一个问题:编译上面的代码,仍然需要引用Person类。不然,去掉import语句,你看能不能编译通过?
所以,反射是为了解决在运行期,对某个实例一无所知的情况下,如何调用其方法。
Class 类
除了int等基本类型外,Java的其他类型全部都是class(包括interface)。例如:
- String
- Object
- Runnable
- Exception
- …
仔细思考,我们可以得出结论:class(包括interface)的本质是数据类型(Type)。无继承关系的数据类型无法赋值:
1 | Number n = new Double(123.456); // OK |
而class是由JVM在执行过程中动态加载的。JVM在第一次读取到一种class类型时,将其加载进内存。
每加载一种class,JVM就为其创建一个Class类型的实例,并关联起来。注意:这里的Class类型是一个名叫Class的class。它长这样:
1 | public final class Class { |
以String类为例,当JVM加载String类时,它首先读取String.class文件到内存,然后,为String类创建一个Class实例并关联起来:
1 | Class cls = new Class(String); |
这个Class实例是JVM内部创建的,如果我们查看JDK源码,可以发现Class类的构造方法是private,只有JVM能创建Class实例,我们自己的Java程序是无法创建Class实例的。
所以,JVM持有的每个Class实例都指向一个数据类型(class或interface):
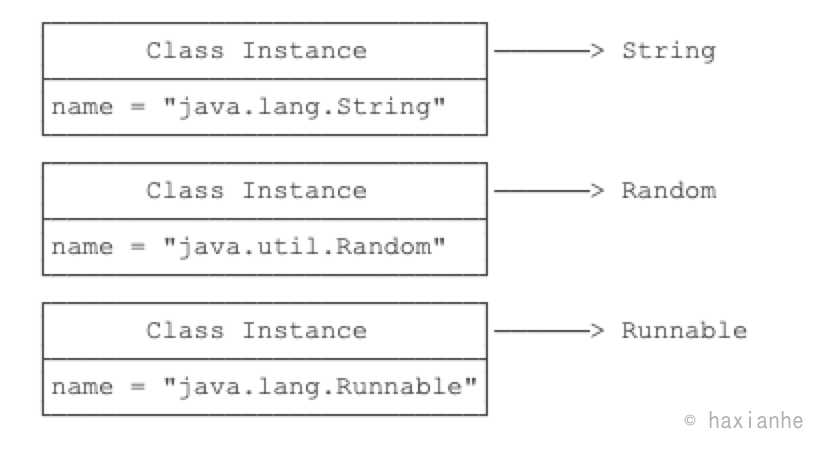
一个Class实例包含了该class的所有完整信息:
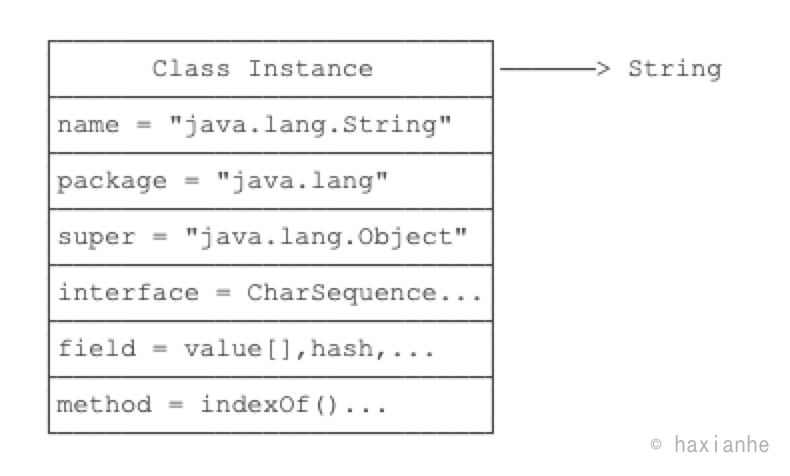
由于JVM为每个加载的class创建了对应的Class实例,并在实例中保存了该class的所有信息,包括类名、包名、父类、实现的接口、所有方法、字段等,因此,如果获取了某个Class实例,我们就可以通过这个Class实例获取到该实例对应的class的所有信息。
这种通过Class实例获取class信息的方法称为反射(Reflection)。
如何获取一个class的Class实例?有三个方法:
方法一:直接通过一个class的静态变量class获取:
1 | Class cls = String.class; |
方法二:如果我们有一个实例变量,可以通过该实例变量提供的getClass()方法获取:
1 | String s = "Hello"; |
方法三:如果知道一个class的完整类名,可以通过静态方法Class.forName()获取:
1 | Class cls = Class.forName("java.lang.String"); |
因为Class实例在JVM中是唯一的,所以,上述方法获取的Class实例是同一个实例。
动态加载
JVM在执行Java程序的时候,并不是一次性把所有用到的class全部加载到内存,而是第一次需要用到class时才加载。例如:
1 | // Main.java |
当执行Main.java时,由于用到了Main,因此,JVM首先会把Main.class加载到内存。然而,并不会加载Person.class,除非程序执行到create()方法,JVM发现需要加载Person类时,才会首次加载Person.class。如果没有执行create()方法,那么Person.class根本就不会被加载。
这就是JVM动态加载class的特性。
动态加载class的特性对于Java程序非常重要。利用JVM动态加载class的特性,我们才能在运行期根据条件加载不同的实现类。例如,Commons Logging总是优先使用Log4j,只有当Log4j不存在时,才使用JDK的logging。利用JVM动态加载特性,大致的实现代码如下:
1 | // Commons Logging优先使用Log4j: |
这就是为什么我们只需要把Log4j的jar包放到classpath中,Commons Logging就会自动使用Log4j的原因。
访问字段/调用方法
对任意的一个Object实例,只要我们获取了它的Class,就可以获取它的一切信息。
我们先看看如何通过Class实例获取字段信息。Class类提供了以下几个方法来获取字段:
- Field getField(name):根据字段名获取某个public的field(包括父类)
- Field getDeclaredField(name):根据字段名获取当前类的某个field(不包括父类)
- Field[] getFields():获取所有public的field(包括父类)
- Field[] getDeclaredFields():获取当前类的所有field(不包括父类)
一个Field对象包含了一个字段的所有信息:
- getName():返回字段名称,例如,”name”;
- getType():返回字段类型,也是一个Class实例,例如,String.class;
- getModifiers():返回字段的修饰符,它是一个int,不同的bit表示不同的含义。
我们已经能通过Class实例获取所有Field对象,同样的,可以通过Class实例获取所有Method信息。Class类提供了以下几个方法来获取Method:
- Method getMethod(name, Class…):获取某个public的Method(包括父类)
- Method getDeclaredMethod(name, Class…):获取当前类的某个Method(不包括父类)
- Method[] getMethods():获取所有public的Method(包括父类)
- Method[] getDeclaredMethods():获取当前类的所有Method(不包括父类)
一个Method对象包含一个方法的所有信息:
- getName():返回方法名称,例如:”getScore”;
- getReturnType():返回方法返回值类型,也是一个Class实例,例如:String.class;
- getParameterTypes():返回方法的参数类型,是一个Class数组,例如:{String.class, int.class};
- getModifiers():返回方法的修饰符,它是一个int,不同的bit表示不同的含义。
通过Class实例获取Constructor的方法如下:
- getConstructor(Class…):获取某个public的Constructor;
- getDeclaredConstructor(Class…):获取某个Constructor;
- getConstructors():获取所有public的Constructor;
- getDeclaredConstructors():获取所有Constructor。
注意Constructor总是当前类定义的构造方法,和父类无关,因此不存在多态的问题。
调用非public的Constructor时,必须首先通过setAccessible(true)设置允许访问。setAccessible(true)可能会失败。
动态代理
我们来比较Java的class和interface的区别:
- 可以实例化class(非abstract);
- 不能实例化interface。
所有interface类型的变量总是通过某个实例向上转型并赋值给接口类型变量的:
1 | CharSequence cs = new StringBuilder(); |
有没有可能不编写实现类,直接在运行期创建某个interface的实例呢?
这是可能的,因为Java标准库提供了一种动态代理(Dynamic Proxy)的机制:可以在运行期动态创建某个interface的实例。
什么叫运行期动态创建?听起来好像很复杂。所谓动态代理,是和静态相对应的。我们来看静态代码怎么写:
定义接口:
1 | public interface Hello { |
编写实现类:
1 | public class HelloWorld implements Hello { |
创建实例,转型为接口并调用:
1 | Hello hello = new HelloWorld(); |
这种方式就是我们通常编写代码的方式。
还有一种方式是动态代码,我们仍然先定义了接口Hello,但是我们并不去编写实现类,而是直接通过JDK提供的一个Proxy.newProxyInstance()创建了一个Hello接口对象。这种没有实现类但是在运行期动态创建了一个接口对象的方式,我们称为动态代码。JDK提供的动态创建接口对象的方式,就叫动态代理。
一个最简单的动态代理实现如下:
1 | import java.lang.reflect.InvocationHandler; |
在运行期动态创建一个interface实例的方法如下:
定义一个InvocationHandler实例,它负责实现接口的方法调用;
通过Proxy.newProxyInstance()创建interface实例,它需要3个参数:
- 使用的ClassLoader,通常就是接口类的ClassLoader;
- 需要实现的接口数组,至少需要传入一个接口进去;
- 用来处理接口方法调用的InvocationHandler实例。
将返回的Object强制转型为接口。
动态代理实际上是JVM在运行期动态创建class字节码并加载的过程,它并没有什么黑魔法,把上面的动态代理改写为静态实现类大概长这样:
1 | public class HelloDynamicProxy implements Hello { |
其实就是JVM帮我们自动编写了一个上述类(不需要源码,可以直接生成字节码),并不存在可以直接实例化接口的黑魔法。
注解
注解的作用
- Annotation是JDK5.0引入的新技术
- Annotation的作用:
- 不是程序本身,可以对程序作出解释(这一点和注释没什么区别)
- 可以被其他程序(比如编译器)读取
- Annotation的格式
- 注解是以“@注释名”在代码中存在的,还可以添加一些参数值,例如:@SuppressWarnings(value=“unchecked”)
- Annotation在哪里使用?
- 可以附加在package,class,method,field等上面,相当于给他们添加了额外的辅助信息。我们可以通过反射机制变成实现对这些元数据的访问。
内置注解
Java 定义了一套注解,共有 7 个,3 个在 java.lang 中,剩下 4 个在 java.lang.annotation 中。
作用在代码的注解是
- @Override - 检查该方法是否是重写方法。如果发现其父类,或者是引用的接口中并没有该方法时,会报编译错误。
- @Deprecated - 标记过时方法。如果使用该方法,会报编译警告。
- @SuppressWarnings - 指示编译器去忽略注解中声明的警告。
作用在其他注解的注解(或者说 元注解)是:
- @Retention - 标识这个注解怎么保存,是只在代码中,还是编入class文件中,或者是在运行时可以通过反射访问。
- @Documented - 标记这些注解是否包含在用户文档中。
- @Target - 标记这个注解应该是哪种 Java 成员。
- @Inherited - 标记这个注解是继承于哪个注解类(默认 注解并没有继承于任何子类)
从 Java 7 开始,额外添加了 3 个注解:
- @SafeVarargs - Java 7 开始支持,忽略任何使用参数为泛型变量的方法或构造函数调用产生的警告。
- @FunctionalInterface - Java 8 开始支持,标识一个匿名函数或函数式接口。
- @Repeatable - Java 8 开始支持,标识某注解可以在同一个声明上使用多次。
定义注解
我们总结一下定义Annotation的步骤:
第一步,用@interface定义注解:
1 | public Report { |
第二步,添加参数、默认值:
1 | public Report { |
把最常用的参数定义为value(),推荐所有参数都尽量设置默认值。
第三步,用元注解配置注解:
1 |
|
其中,必须设置@Target和@Retention,@Retention一般设置为RUNTIME,因为我们自定义的注解通常要求在运行期读取。一般情况下,不必写@Inherited和@Repeatable。
处理注解
Java的注解本身对代码逻辑没有任何影响。根据@Retention的配置:
- SOURCE类型的注解在编译期就被丢掉了;
- CLASS类型的注解仅保存在class文件中,它们不会被加载进JVM;
- RUNTIME类型的注解会被加载进JVM,并且在运行期可以被程序读取。
如何使用注解完全由工具决定。SOURCE类型的注解主要由编译器使用,因此我们一般只使用,不编写。CLASS类型的注解主要由底层工具库使用,涉及到class的加载,一般我们很少用到。只有RUNTIME类型的注解不但要使用,还经常需要编写。
因此,我们只讨论如何读取RUNTIME类型的注解。
因为注解定义后也是一种class,所有的注解都继承自java.lang.annotation.Annotation,因此,读取注解,需要使用反射API。
Java提供的使用反射API读取Annotation的方法包括:
判断某个注解是否存在于Class、Field、Method或Constructor:
- Class.isAnnotationPresent(Class)
- Field.isAnnotationPresent(Class)
- Method.isAnnotationPresent(Class)
- Constructor.isAnnotationPresent(Class)
例如:
1 | // 判断@Report是否存在于Person类: |
使用反射API读取Annotation:
- Class.getAnnotation(Class)
- Field.getAnnotation(Class)
- Method.getAnnotation(Class)
- Constructor.getAnnotation(Class)
例如:
1 | // 获取Person定义的@Report注解: |
使用反射API读取Annotation有两种方法。方法一是先判断Annotation是否存在,如果存在,就直接读取:
1 | Class cls = Person.class; |
第二种方法是直接读取Annotation,如果Annotation不存在,将返回null:
1 | Class cls = Person.class; |
读取方法、字段和构造方法的Annotation和Class类似。但要读取方法参数的Annotation就比较麻烦一点,因为方法参数本身可以看成一个数组,而每个参数又可以定义多个注解,所以,一次获取方法参数的所有注解就必须用一个二维数组来表示。例如,对于以下方法定义的注解:
1 | public void hello( String name, String prefix) { |
要读取方法参数的注解,我们先用反射获取Method实例,然后读取方法参数的所有注解:
1 | // 获取Method实例: |
使用注解
注解如何使用,完全由程序自己决定。例如,JUnit是一个测试框架,它会自动运行所有标记为@Test的方法。
我们来看一个@Range注解,我们希望用它来定义一个String字段的规则:字段长度满足@Range的参数定义:
1 |
|
在某个JavaBean中,我们可以使用该注解:
1 | public class Person { |
但是,定义了注解,本身对程序逻辑没有任何影响。我们必须自己编写代码来使用注解。这里,我们编写一个Person实例的检查方法,它可以检查Person实例的String字段长度是否满足@Range的定义:
1 | void check(Person person) throws IllegalArgumentException, ReflectiveOperationException { |
这样一来,我们通过@Range注解,配合check()方法,就可以完成Person实例的检查。注意检查逻辑完全是我们自己编写的,JVM不会自动给注解添加任何额外的逻辑。
泛型
什么是泛型
- 泛型就是编写模板代码来适应任意类型;
- 泛型的好处是使用时不必对类型进行强制转换,它通过编译器对类型进行检查;
- 注意泛型的继承关系:可以把ArrayList
向上转型为List (T不能变!),但不能把ArrayList 向上转型为ArrayList (T不能变成父类)。
泛型就是定义一种模板,例如ArrayList
1 | ArrayList<String> strList = new ArrayList<String>(); |
由编译器针对类型作检查:
1 | strList.add("hello"); // OK |
这样一来,既实现了编写一次,万能匹配,又通过编译器保证了类型安全:这就是泛型。
向上转型
在Java标准库中的ArrayList
1 | public class ArrayList<T> implements List<T> { |
即类型ArrayList
要特别注意:不能把ArrayList
使用泛型
使用泛型时,把泛型参数
可以省略编译器能自动推断出的类型,例如:List
不指定泛型参数类型时,编译器会给出警告,且只能将
可以在接口中定义泛型类型,实现此接口的类必须实现正确的泛型类型。
编写泛型
编写泛型类比普通类要复杂。通常来说,泛型类一般用在集合类中,例如ArrayList
如果我们确实需要编写一个泛型类,那么,应该如何编写它?
可以按照以下步骤来编写一个泛型类。
首先,按照某种类型,例如:String,来编写类:
1 | public class Pair { |
然后,,把特定类型String替换为T,并申明
1 | public class Pair<T> { |
编写泛型时,需要定义泛型类型
; 静态方法不能引用泛型类型
,必须定义其他类型(例如 )来实现静态泛型方法; 泛型可以同时定义多种类型,例如Map<K, V>。
擦拭法
泛型是一种类似”模板代码“的技术,不同语言的泛型实现方式不一定相同。
Java语言的泛型实现方式是擦拭法(Type Erasure)。
所谓擦拭法是指,虚拟机对泛型其实一无所知,所有的工作都是编译器做的。
例如,我们编写了一个泛型类Pair
1 | public class Pair<T> { |
而虚拟机根本不知道泛型。这是虚拟机执行的代码:
1 | public class Pair { |
因此,Java使用擦拭法实现泛型,导致了:
- 编译器把类型
视为Object; - 编译器根据
实现安全的强制转型。
使用泛型的时候,我们编写的代码也是编译器看到的代码:
1 | Pair<String> p = new Pair<>("Hello", "world"); |
而虚拟机执行的代码并没有泛型:
1 | Pair p = new Pair("Hello", "world"); |
所以,Java的泛型是由编译器在编译时实行的,编译器内部永远把所有类型T视为Object处理,但是,在需要转型的时候,编译器会根据T的类型自动为我们实行安全地强制转型。
了解了Java泛型的实现方式——擦拭法,我们就知道了Java泛型的局限,擦拭法决定了泛型
- 不能是基本类型,例如:int;
- 不能获取带泛型类型的Class,例如:Pair
.class; - 不能判断带泛型类型的类型,例如:x instanceof Pair
; - 不能实例化T类型,例如:new T()。
泛型方法要防止重复定义方法,例如:public boolean equals(T obj);
子类可以获取父类的泛型类型
