背景
最近要对帐单历史数据清洗,发现清洗后的数据存在乱序问题。简单来说就是补10月份补1条1月份的账单,页面展示的时候这条账单会出现9月份数据之前。
原因是因为这里用的是游标分页,而分页的字段是id(严格自增),所以10月份补的账单id会比9月份的账单id大,展示的时候也就会展示在前面。
目标
移动端按照时间序展示账单。
常规方案
在设计具体方案之前对后端实现分页的方法做了一下简单梳理。
目前后端分页设计一般分为两种类型:传统网站比较常见的电梯式分页布局及移动端比较常见的流式分页布局。
传统网站电梯式分页布局
电梯式分页布局在传统网站中非常常见,比如百度、淘宝:

它的特点是在网站的底部有分页栏,用户不仅可以点击上一页、下一页浏览数据,还可以直接点击页码跳转到特定页,所以电梯式分页的的 SQL 查询(以下称为传统分页)也比较统一,基本上为前端提供页数及每页的数量,后端套用下面的 SQL 查询语句:
1 | #currentPage 为当前页数(以 1 开始),pagingSize 为每页的数据量 |
流式分页布局
流式分页布局在移动端比较流行,因为移动端的屏幕尺寸普遍较小,会导致分页栏不容易点击。并且移动端拥有良好的滑动体验,向上滑动加载更多,向下滑动刷新的操作方式更加便利。
流式分页布局在后端的处理上,有两种实现方案,一种是直接将传统分页逻辑套用到移动端流式分页上,另一种是游标分页。
直接将传统分页套用到移动端流式分页上
直接将传统分页套用到移动端流式分页上的主要问题如下:
数据重复
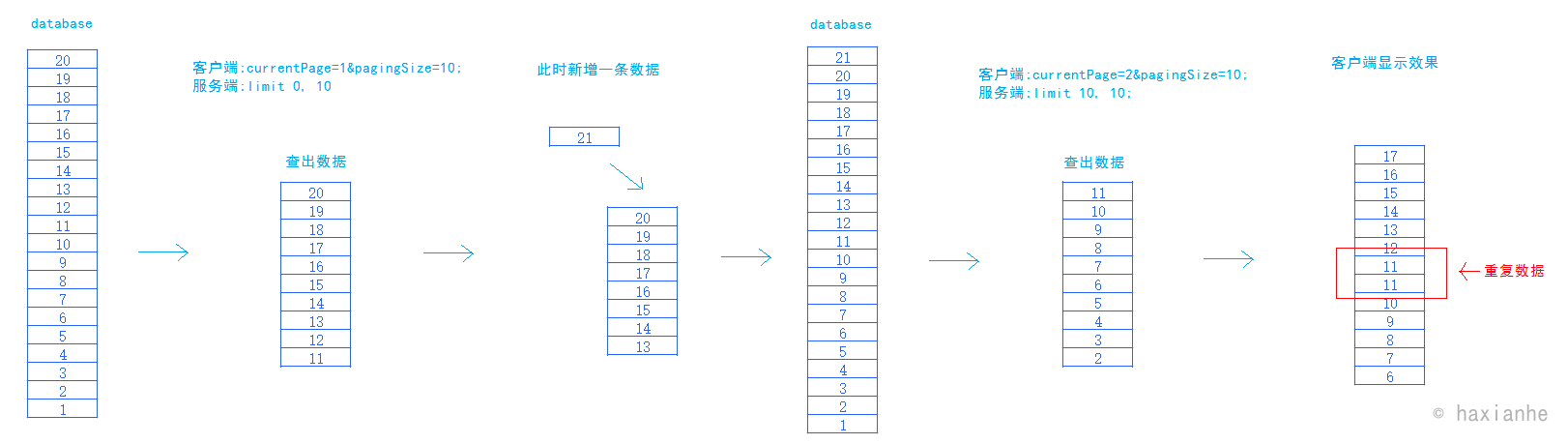
数据缺失
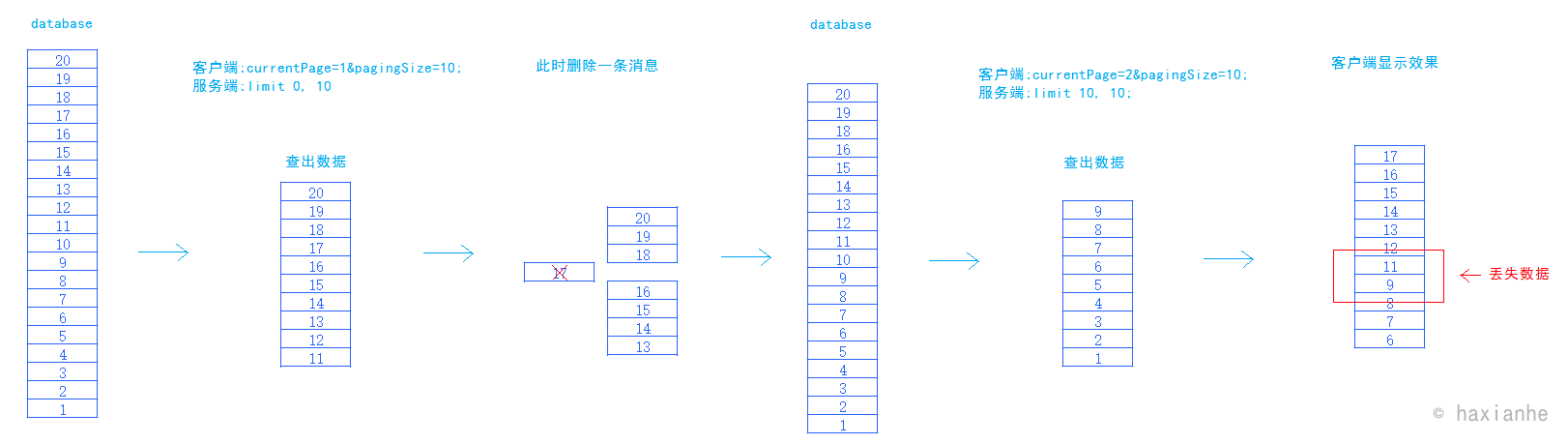
效率低
使用 limit 在数据量小的时候并不会有效率问题,但是当数据偏移量很大时性能会开始急剧下降。
游标分页
游标分页则不需要提供当前页码,而是提供当前页的起始位置(也称为游标)用于定位,游标分页的 SQL 语句如下:
1 | #cursor 为上一页最后一条新闻的 create_date(如果是第一页则为当前时间),pagingSize 为每页的数据量 |
传统分页的偏移量是固定的,所以会因为数据的新增或减少导致接下来加载数据重复或丢失。而游标分页则不会出现这种情况,因为当数据发生新增和减少时,游标的位置也会相对变化。
解决方案
经过分析发现,目前的游标分页方案还是要采用的,现在的问题是游标字段id不能代表实际在页面上要展示的顺序。
方案一:换一个游标字段,将id换成create_time。存在问题,当create_time相同时,非第一页数据会丢掉。
方案二:在方案一的基础上只要能保证同一时间只有1条记录就没问题了,比如根据时间生成id,时间大的id也大。
方案三:我这里遇到的问题不太好通过根据时间生成id来解决(id生成不在我这边),所以增加一个冗余字段,通过将账单实际生成时间和id拼接来达到先生成的账单一定先展示,同一时间生成的账单按照id大小顺序展示的目的。
这里只能采用方案三来解决这个问题,mysql索引长度限制为131个字节,经过计算13位的时间戳+18位的id完全够用。
问题一:未来时间戳长度会不会增加?
经过计算200年内不会增长
1 | (9999999999999-1664635278000)/(365*24*60*60*1000) = 264.31(年) |
问题二:id会不会增长?
之前为了保证id的严格自增,id的生成采用的是 snowflake 算法生成的,所以不会增长
生成冗余字段规则如下:
1 | sort_id = (create_time * 1000000000000000000) + id; |
总结
- 分页方案主要分传统PC电梯分页和移动端流式分页
- 用传统电梯分页方案实现流式分页主要的问题有数据重复、数据丢失、数据量大时性能低。
- 流式分页主要通过游标分页方案来实现
- 当出现因为洗数据导致分页乱序问题时,最直接的方案时将游标字段改为一个和数据生成时间相关的字段。
- 如果数据量比较大数据统一时间可能存在多条记录要么想办法保证相同时间内只能有一条记录,要么增加一个冗余字段将生成时间和id冗余到一起。
